

1.1 随机函数的定义与分类
随机函数本质上是一个输出不可预测结果的数学工具。它像一台自动售货机——你按下按钮,但每次掉出来的糖果口味可能都不一样。在计算机科学中,这种“不可预测性”成为模拟现实世界不确定性的关键手段。
常见的随机函数可以分为离散型和连续型两大类。离散随机函数就像掷骰子,结果只能是1到6的整数;连续随机函数则像测量一条河流的深度,可能得到任意精度的数值。我记得第一次用随机函数模拟抛硬币实验时,连续十次都是正面——这种看似不可能的结果恰恰证明了随机性的魅力。
1.2 伪随机与真随机的区别
计算机领域存在一个有趣的事实:绝大多数所谓的“随机”其实都是伪随机。伪随机数生成器通过确定的数学公式产生序列,只要知道初始状态就能预测所有后续结果。这就像按照固定食谱做菜——虽然每次味道略有变化,但基本原料和步骤都是预设的。
真随机则依赖于物理世界的不可预测现象。比如测量大气噪声、放射性衰变时间,或者你敲击键盘的精确时间间隔。这些方法产生的随机数理论上完全不可预测。我曾经参与过一个需要高度安全性的项目,最终选择了基于硬件噪声的真随机源,那种踏实感确实令人印象深刻。
1.3 随机数生成器的核心算法
线性同余生成器是最经典的伪随机算法之一。它通过一个简单的递推公式工作:新数 = (a * 旧数 + c) mod m。虽然计算简单,但周期性和统计特性需要精心设计参数。现代应用中,梅森旋转算法更为流行,其超长周期达到2^19937-1,几乎能满足所有普通需求。
密码学安全场景则倾向于使用Blum Blum Shub或基于哈希函数的算法。这些方法牺牲了部分速度,但确保了即使知道部分输出也无法推测其他结果。选择算法时需要在速度、周期长度和安全性之间找到平衡点,这往往取决于具体应用场景的实际需求。
2.1 random模块常用函数详解
Python的random模块就像程序员的魔术袋,装满了各种制造惊喜的工具。random()函数是最基础的成员,它返回[0.0, 1.0)范围内的浮点数——这个看似简单的功能却能构建出复杂的随机世界。
randint(a, b)让你能像掷骰子一样获得指定范围内的整数。我特别喜欢用choice(seq)从列表中随机挑选元素,它让程序的选择变得生动有趣。shuffle(lst)则像洗牌高手,能在瞬间打乱任何序列的顺序。有一次我需要随机分配工作任务,就用shuffle把员工列表重新排列,整个过程公平又高效。
uniform(a, b)提供了连续区间内的随机浮点数,而gauss(mu, sigma)则能生成符合正态分布的值。这些函数组合起来,几乎能模拟现实世界中的任何随机现象。
2.2 numpy.random模块的高级功能
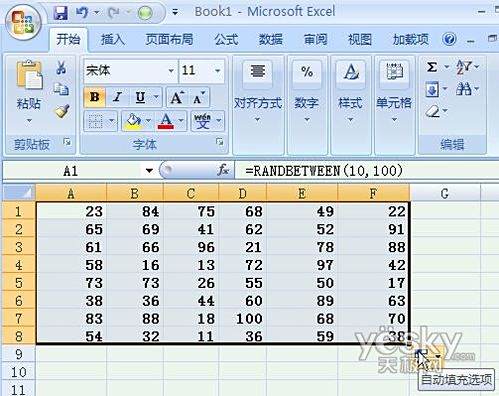
当需要处理大量随机数时,numpy.random展现出真正的威力。它能一次性生成整个数组的随机值,这种向量化操作让效率提升数个数量级。randn(d0, d1, ..., dn)直接生成标准正态分布数组,对于数据科学工作来说简直是天赐之物。
我曾在机器学习项目中需要生成十万个服从特定分布的样本,numpy.random仅用一行代码就解决了问题。它的random_sample(size)函数支持多种分布类型,从均匀分布到贝塔分布,几乎囊括了统计学中的所有常见分布。
randint(low, high, size)在指定范围内生成整数数组的能力特别实用。相比标准random模块,numpy的批量生成能力让它在科学计算和大数据处理中占据绝对优势。
2.3 随机种子设置与可重复性控制
设置随机种子就像给随机性加上缰绳。random.seed(42)这个简单的调用能让随机序列在每次运行时保持一致。这种可重复性在调试和测试中至关重要——你总不希望因为随机性而无法复现那个棘手的bug。
种子可以是任何哈希对象,但通常使用整数。有趣的是,相同的种子在不同Python版本中可能产生不同序列,这是需要注意的兼容性问题。numpy.random也提供类似的seed()函数,确保科学实验的可重复性。
我记得有个数据分析项目需要多次运行相同随机过程来验证稳定性,设置固定种子让每次比较都建立在相同基础上。这种控制能力让随机性从混乱变成了可管理的工具。
2.4 常见分布类型及应用场景
不同的随机需求对应着不同的概率分布。均匀分布适合模拟完全公平的选择,比如抽奖或随机分配。正态分布在自然界中无处不在,从身高分布到测量误差都能见到它的身影。
指数分布常用于模拟等待时间,比如客户到达间隔或设备寿命。泊松分布则擅长描述单位时间内随机事件发生的次数,比如网站访问量或电话呼叫频率。
二项分布对应着多次独立的是非试验,比如质检抽样中的次品数量。在实际项目中,理解这些分布的特性就像拥有不同的调色盘——每个分布都能为特定场景调配出最合适的随机色彩。
3.1 游戏道具掉落机制设计
游戏中的战利品系统就像精心设计的惊喜盲盒。开发者通过权重配置控制稀有道具的出现概率,让每次击败敌人都有独特的期待感。常见的做法是使用分层随机——先决定掉落类别,再在类别内随机选择具体物品。
我曾经参与一个RPG游戏的掉落系统设计。普通怪物有70%概率掉落普通物品,25%概率掉落精良装备,5%概率出现史诗级道具。这种梯度设计既保持了游戏的惊喜感,又避免了稀有物品泛滥贬值。使用random.choices()函数配合权重参数,能够优雅地实现这种多概率选择。
更复杂的系统还会引入保底机制。比如连续多次未获得稀有道具时,概率会逐渐提升。这种设计缓解了玩家的挫败感,让随机系统显得更加人性化。在实际编码中,我们通过记录玩家历史掉落数据来动态调整权重,这种动态平衡让游戏体验更加流畅。
3.2 敌人AI行为随机化
智能的敌人不应该像机器人一样可预测。通过给AI行为注入适当的随机性,每个遭遇战都能保持新鲜感。基本的做法是在行为决策树中引入概率分支——敌人有60%概率选择攻击,30%概率防御,10%概率使用特殊技能。
我观察过很多玩家反馈,他们特别讨厌模式化的敌人行为。有个射击游戏项目,我们让敌人在掩体后的停留时间随机化,结果玩家评价明显提升。这种不可预测性迫使玩家时刻保持警惕,而不是依赖固定的应对套路。
更高级的随机化包括攻击节奏变化、移动路径选择和技能释放时机。使用numpy.random.normal()可以生成符合正态分布的数值,让大多数行为集中在合理范围内,偶尔出现极端情况增加变数。这种设计让每个敌人都显得有自己的“个性”。
3.3 地图生成与关卡设计
程序化生成技术让游戏拥有几乎无限的重玩价值。《我的世界》那样的沙盒游戏完美展示了随机地图的魅力。核心思路是将预制的模块通过随机算法组合,创造出既熟悉又陌生的游戏空间。
地牢生成通常采用随机房间布局。先随机决定房间数量和大小,再用走廊连接它们。perlin噪声算法能够生成自然的地形起伏,让山脉和河流的分布看起来更加真实。我曾经尝试用random.sample()来随机选择地形特征组合,结果每次都能产生独特的地图景观。
关卡难度也可以通过随机元素调节。敌人数量、道具分布、陷阱位置的变化,让同一关卡每次游玩都有不同挑战。重要的是保持核心体验一致,只在外围元素上引入随机性。玩家既享受新鲜感,又不会觉得完全陌生。
3.4 游戏平衡性调整与测试
随机性是一把双刃剑,过度使用会破坏游戏平衡。好的设计需要在确定性和随机性之间找到甜蜜点。A/B测试是验证平衡性的有效方法——让不同玩家群体体验不同参数配置,收集数据进行分析。
伤害浮动是常见的随机平衡设计。基础伤害值加上随机偏移,既避免了完全固定的单调,又防止了极端运气影响战局。我们通常使用random.uniform()在±10%范围内浮动,这个幅度足够产生变化,又不会颠覆战术选择。
测试阶段需要大量模拟运行。设置固定随机种子可以复现特定场景,帮助调试平衡问题。我习惯在开发日志中记录使用的种子值,当玩家报告异常情况时,能够快速重现当时的游戏状态。这种可控的随机性让平衡调整变得有据可依。