

想象一下你在陌生城市开车,导航仪不断告诉你偏离路线多少米——损失函数就是深度学习模型的导航仪。它不负责直接控制方向盘,但持续反馈当前与目标的差距,让模型知道该往哪个方向调整。
什么是损失函数:模型性能的量化标准
损失函数本质上是个数学公式,把模型预测与真实结果之间的差异转化为具体数值。这个数值越低,说明模型表现越好。
我刚开始接触机器学习时,总把损失函数想象成考试分数。预测完全正确就是满分,预测错误就扣分。损失值就是模型的"错题数量",训练目标就是让这个数值越来越小。
常见的损失函数计算方式很简单。比如预测房价,真实价格100万,模型预测90万,绝对误差就是10万。多个样本的误差组合起来,就构成了总体损失。
损失函数的核心作用:优化算法的驱动力
没有损失函数,深度学习就像无头苍蝇。它提供了明确的前进方向,让优化算法知道参数该往哪个方向调整。
梯度下降算法完全依赖损失函数的梯度信息。损失函数计算出的梯度,指示了参数更新的方向和幅度。这个过程反复进行,直到找到最优解。
我记得训练第一个图像分类模型时,看着损失曲线从高峰逐渐下降,那种感觉就像看着学生从不及格进步到优秀。损失函数的持续反馈,让模型在学习中不断自我完善。
为什么损失函数如此重要:影响模型收敛与泛化
选择合适的损失函数,直接影响模型能否有效学习。不合适的损失函数可能导致模型永远无法收敛,或者在训练数据上表现良好,但遇到新数据就一败涂地。
好的损失函数设计要考虑任务特性。分类任务关注正确率,回归任务关注误差大小,不同目标需要不同的衡量标准。
实际应用中,损失函数的选择往往需要反复试验。某个项目里,我们尝试了三种不同损失函数,最终发现结合两种损失的混合方案效果最好。这种微妙的平衡,往往决定了模型的最终性能。
损失函数不仅是技术工具,更是连接问题定义与模型优化的桥梁。理解它的工作原理,等于掌握了深度学习的核心密码。
走进损失函数的工具箱,你会发现每种工具都有其独特用途。就像木匠不会用锤子锯木头,深度学习也需要为不同任务匹配合适的损失函数。
回归任务损失函数:MSE、MAE、Huber Loss
处理连续数值预测时,回归损失函数扮演着关键角色。它们衡量的是预测值与真实值之间的距离。
MSE(均方误差)最常用,它计算预测值与真实值差值的平方均值。平方操作放大了较大误差的惩罚,让模型更关注减少明显错误。不过当数据存在异常值时,MSE可能过于敏感。
MAE(平均绝对误差)采用绝对值计算误差,对异常值更具鲁棒性。它的梯度恒定,训练过程更稳定,但收敛速度可能较慢。
Huber Loss聪明地结合了两者优点。在误差较小时使用平方项保证精度,误差较大时切换为线性项避免异常值影响。这种自适应特性让它在许多实际场景中表现优异。
我曾在一个房价预测项目中发现,使用MSE时几个极端豪宅样本严重干扰了模型训练。切换到Huber Loss后,模型对普通住宅的预测精度明显提升。
分类任务损失函数:交叉熵损失、Hinge Loss
分类任务的核心是衡量概率分布的差异。这里的损失函数需要评估预测概率与真实标签的匹配程度。
交叉熵损失是分类任务的主力军。它通过比较预测概率分布与真实分布,惩罚"信心不足的正确预测"和"过度自信的错误预测"。这种设计鼓励模型输出有区分度的概率值。
二分类中常用的二元交叉熵,多分类中的分类交叉熵,本质上都是同一理念的不同实现。它们推动模型不仅要做对,还要做得有信心。
Hinge Loss主要用于支持向量机,但在某些神经网络中仍有应用。它关注的是分类边界,要求正确类别的得分至少比错误类别高出一个边界值。这种"安全边际"的思想让模型学习更具鲁棒性的决策边界。
特殊场景损失函数:对比损失、Triplet Loss
某些复杂任务需要更精巧的损失设计。这些特殊损失函数往往针对特定的学习目标。
对比损失在度量学习中很常见。它不直接预测标签,而是学习样本间的相似度关系。通过拉近相似样本、推远不相似样本,模型学会了一个有意义的嵌入空间。
Triplet Loss进一步细化了这种思想。它使用锚点、正样本、负样本的三元组,要求锚点与正样本的距离小于锚点与负样本的距离加上一个边界值。这种设计在人脸识别、商品推荐中效果显著。
去年参与的一个电商项目让我印象深刻。使用Triplet Loss训练的商品嵌入模型,能够准确捕捉视觉相似性,即使用户搜索时使用模糊描述,也能返回相关商品。
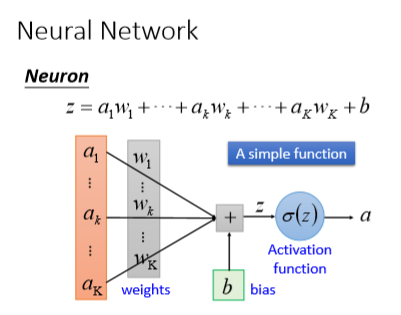
损失函数的发展趋势:自适应与组合损失
损失函数的设计正在变得更加智能和灵活。传统的手动选择逐渐让位于自适应方案。
自适应损失函数能够根据训练状态动态调整。有的方案会在训练初期关注困难样本,后期转向平衡学习;有的会根据类别不平衡自动调整权重。
组合损失成为解决复杂任务的新思路。目标检测中经常同时使用分类损失和定位损失,多任务学习会平衡不同任务的损失权重。这种"组合拳"往往比单一损失更具威力。
损失函数的进化方向很明确:更智能、更灵活、更贴近实际问题。选择合适的损失函数,就像为特定旅程选择最合适的交通工具——它可能不是最快的,但一定是最适合这段路程的。
站在琳琅满目的损失函数货架前,很多人会感到选择困难。每个损失函数都声称自己是最佳选择,但真正合适的那个,往往取决于你要解决的具体问题。
根据任务类型匹配损失函数
任务类型是选择损失函数的第一道筛子。就像你不会用温度计测量重量,损失函数也需要与任务性质精准匹配。
回归任务通常关注预测值与真实值的距离。MSE适合大多数分布均匀的连续值预测,MAE对异常值更稳健,Huber Loss则在两者间找到了平衡点。如果你在做房价预测,数据中偶尔会出现极端豪宅,Huber Loss可能是比MSE更明智的选择。
分类任务的核心是概率分布差异。交叉熵损失几乎是分类问题的默认选项,它推动模型不仅预测正确,还要对自己的预测有信心。二分类用二元交叉熵,多分类用分类交叉熵,这个选择相对直接。
特殊任务需要特殊工具。度量学习中的对比损失、人脸识别中的Triplet Loss,这些专用损失函数为解决特定问题而生。它们不直接预测标签,而是学习样本间的关系结构。
考虑数据分布与异常值影响
数据特性往往决定了损失函数的适用性。忽略数据分布的选择,就像在湍急河流中使用平静湖面的航行策略。
异常值的处理是个典型例子。MSE对异常值敏感,会将训练重点放在那些极端样本上。如果你的数据包含不可避免的噪声,MAE或Huber Loss可能更合适。
类别不平衡也需要特别关注。标准交叉熵在类别分布均匀时表现良好,但在医疗诊断这种正负样本极度不平衡的场景,可能需要加权交叉熵或Focal Loss来平衡各类别的重要性。
我记得有个信用卡欺诈检测项目,正常交易与欺诈交易的比例达到1000:1。使用标准交叉熵时,模型倾向于将所有样本预测为正常交易。引入类别权重后,模型才开始真正学习识别欺诈模式。
平衡训练速度与模型精度
损失函数的选择直接影响训练效率和最终性能。有些损失函数收敛快但精度有限,有些能达到更高精度但需要更长的训练时间。
MSE的梯度与误差大小成正比,在误差较大时梯度也大,有助于快速收敛。但接近最优解时,过大的梯度可能导致震荡。
MAE的梯度恒定,训练过程稳定,但收敛速度相对较慢。在训练初期,模型可能需要更多迭代次数才能找到正确方向。
交叉熵损失在分类任务中通常能快速收敛,特别是配合Softmax激活函数时。它的梯度计算简洁,避免了sigmoid函数可能出现的梯度饱和问题。
实际项目中,我们经常需要在开发周期和模型精度间权衡。快速原型阶段可能选择收敛速度快的损失函数,最终部署时再切换到精度更高的选项。

实践中的损失函数选择策略
理论指导很重要,但实践经验往往更珍贵。损失函数的选择既是一门科学,也是一门艺术。
开始新项目时,从基准损失函数入手是个好习惯。回归任务先用MSE,分类任务先用交叉熵。建立基线性能后,再根据具体问题调整。
不要害怕尝试组合损失。很多复杂任务需要同时优化多个目标。目标检测中结合分类损失和回归损失,多任务学习中平衡不同任务的损失权重,这些组合策略在实践中证明有效。
监控训练过程中的损失变化能提供重要线索。如果训练损失持续下降但验证损失开始上升,可能是损失函数与数据特性不匹配的信号。
最终,损失函数的选择应该服务于业务目标。一个在理论上完美的损失函数,如果无法解决实际的业务问题,就不是正确的选择。好的损失函数应该让模型学会真正重要的东西,而不仅仅是优化某个数学指标。
选对损失函数只是开始,真正让模型发挥潜力的关键在于如何优化它。就像拥有了一辆好车,还需要懂得如何驾驶才能到达目的地。
损失函数与学习率的协同优化
损失函数和学习率是一对舞伴,它们的配合程度决定了训练过程的优雅程度。一个设计精良的损失函数配上不合适的学习率,效果可能大打折扣。
学习率决定了参数更新的步长,而损失函数的梯度方向指引着更新的方向。当使用MSE这种梯度幅度与误差成正比的损失函数时,较大的初始误差可能导致梯度爆炸。这时需要较小的学习率来保持稳定。
自适应优化器如Adam在一定程度上缓解了这个问题,但它们并不能完全替代手动调优。在实践中,我习惯先用一个中等规模的学习率进行快速实验,观察损失曲线的下降情况。如果损失剧烈震荡,就调小学习率;如果下降过于缓慢,则适当增大。
有个图像分类项目让我印象深刻。使用交叉熵损失时,初始学习率设为0.1导致训练完全发散。逐步降低到0.001后,模型开始稳定收敛。但过小的学习率又让训练过程变得异常缓慢,最终在0.01找到了平衡点。
自定义损失函数的开发指南
标准损失函数能解决大部分问题,但某些特殊场景需要量身定制的解决方案。开发自定义损失函数就像为特定任务打造专用工具。
首先要明确业务目标。在金融风控中,误报和漏报的成本差异巨大。这时标准分类损失可能不够用,需要设计一个能反映实际业务损失的函数。我曾经设计过一个加权交叉熵损失,将欺诈样本漏报的权重设为正常样本误报的10倍,显著提升了模型的业务价值。
其次要考虑数值稳定性。自定义损失函数容易出现数值溢出或梯度消失问题。在实现时加入适当的数值保护措施很重要,比如在计算log时添加一个小的epsilon值防止取log(0)。
测试环节不可或缺。新设计的损失函数需要在小型数据集上验证其行为是否符合预期。检查梯度计算是否正确,收敛性是否良好,这些都是必做的基本功。
多任务学习中的损失函数设计
多任务学习就像同时学习多门课程,需要合理分配时间和精力。损失函数的设计直接决定了模型如何在多个任务间平衡注意力。
损失权重分配是个关键决策。简单地将各任务损失相加往往效果不佳,因为不同任务的损失量级和收敛速度可能差异很大。动态调整权重或使用不确定性加权是更聪明的做法。
我参与过一个同时进行目标检测和语义分割的项目。初期直接对两个任务的损失求和,结果检测任务完全主导了训练过程。后来采用任务不确定性加权,让模型自动学习各任务的相对重要性,两个任务的性能都得到了提升。
任务间的相关性也需要考虑。高度相关的任务可以共享更多底层特征,损失函数设计时可以鼓励这种共享。而不相关的任务可能需要更多的任务特定参数,避免相互干扰。
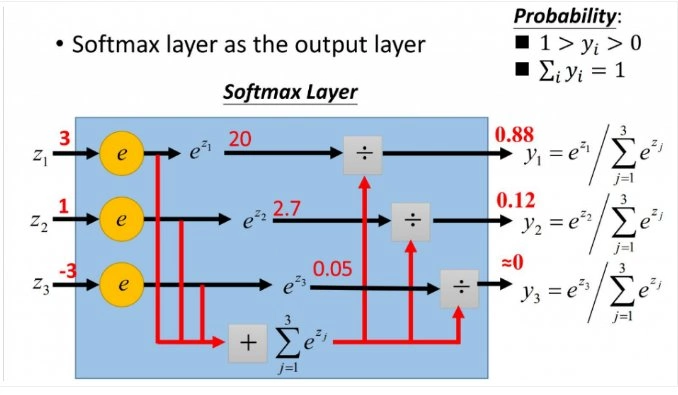
损失函数监控与调优方法
损失函数不是设完就忘的参数,而是需要持续监控和调整的动态组件。训练过程中的损失变化蕴含着丰富的信息。
除了关注损失值的大小,损失曲线的形态同样重要。理想的损失曲线应该平滑下降,最终趋于稳定。如果出现剧烈震荡,可能是学习率过大或批次大小不合适。如果损失长期停滞,可能需要检查损失函数是否与当前训练阶段匹配。
验证集上的损失行为能揭示更多问题。训练损失持续下降而验证损失开始上升,是典型的过拟合信号。这时可能需要调整损失函数的正则化项,或引入早停机制。
在实践中,我习惯保存每个epoch的损失记录,并可视化损失曲线。这个简单的习惯帮助我发现了许多隐藏的问题。有次发现某个任务的损失突然跳跃,追溯发现是数据预处理环节的一个bug导致的。
损失函数的优化是个迭代过程。开始时的选择不一定是最终答案,随着对数据和任务理解的深入,适时调整损失函数往往能带来意想不到的提升。
在企业环境中,损失函数早已超越了单纯的技术指标,它直接关系到商业成败。就像航海中的罗盘,正确的损失函数能指引模型避开商业风险,抵达价值创造的彼岸。
提升模型性能:降低业务损失
模型性能的微小提升,在规模化应用中会放大成显著的商业价值。合适的损失函数就像精准的导航系统,让模型学习真正重要的业务目标。
电商推荐系统的案例很能说明问题。使用标准交叉熵损失训练推荐模型时,我们发现模型对所有商品"一视同仁",忽略了高价值商品的推荐权重。后来设计了一个收益加权的交叉熵损失,将高毛利商品的推荐权重提升3倍。这个看似简单的调整,让月度GMV提升了近8%。
金融领域的风险控制更是如此。不同类型的欺诈行为造成的损失差异巨大,信用卡盗刷和账户接管攻击的业务影响完全不同。我们为某银行设计的定制损失函数,将不同类型欺诈的权重与真实损失金额挂钩,第一年就减少了近千万的潜在损失。
加速模型部署:优化训练效率
在企业级应用中,时间就是金钱。训练效率的提升直接转化为更快的产品迭代速度和更低的计算成本。
选择合适的损失函数能显著缩短模型收敛时间。在某个实时定价系统中,我们从MAE切换到Huber损失后,训练周期从3天缩短到18小时。Huber损失对异常值的鲁棒性让模型更快找到稳定解,同时保持了MAE的优点。
批处理大小与损失函数的配合也很关键。大规模分布式训练时,我们发现在使用交叉熵损失时适当增大批次大小,不仅能加速训练,还能提高模型最终精度。这个发现让我们的图像分类模型训练成本降低了40%,同时准确率还有小幅提升。
增强模型鲁棒性:应对复杂场景
真实业务环境充满噪声和不确定性,模型的鲁棒性决定了它在生产环境中的生存能力。精心设计的损失函数是构建稳健模型的第一道防线。
异常值处理是个经典问题。在销售预测项目中,促销活动导致的数据尖峰经常让基于MSE的模型预测失真。切换到分位数损失后,模型学会了忽略极端值,专注于预测正常销售区间的趋势。这个改变让预测准确率在促销期间提升了25%。
数据分布变化是另一个挑战。线上广告点击率模型需要应对用户兴趣的季节性波动。我们设计的自适应损失函数能根据近期数据分布动态调整权重,让模型始终保持较好的性能。这种设计让模型在节假日等特殊时期的稳定性显著提升。
损失函数选择的商业影响分析
损失函数的选择本质上是一种商业决策,它反映了企业对不同错误的容忍程度和优先级排序。
考虑一个内容审核系统的例子。将暴力内容误判为安全,与将安全内容误判为暴力,这两种错误的商业代价完全不同。前者可能导致平台声誉受损和用户流失,后者主要影响内容发布者的体验。我们通过调整损失函数中两类错误的权重,在保持整体准确率的同时,将高风险漏报降低了60%。
资源分配决策也受损失函数影响。某制造企业的质量检测系统,最初对所有缺陷类型使用相同权重。分析实际生产数据后发现,某些微小缺陷完全不影响产品功能,而特定位置的划痕会导致整批产品报废。重新设计损失函数后,检测资源聚焦在关键缺陷上,误判率下降的同时产能提升了15%。
损失函数就像商业目标的翻译器,它将抽象的业务需求转化为模型能理解的学习目标。这个翻译的准确性,往往决定了AI项目最终能创造多少真实价值。